Introduction
Whenever a new paper is released using some type of scraped data, most of my peers in the social science community get baffled at how researchers can do this. In fact, many social scientists can’t even think of research questions that can be addressed with this type of data simply because they don’t know it’s even possible. As the old saying goes, when you have a hammer, every problem looks like a nail.
With the increasing amount of data being collected on a daily basis, it is eminent that scientists start getting familiar with new technologies that can help answer old questions. Moreover, we need to be adventurous about cutting edge data sources as they can also allow us to ask new questions which weren’t even thought of in the past.
In this tutorial I’ll be guiding you through the basics of web scraping using R and the xml2 package. I’ll begin with a simple example using fake data and elaborate further by trying to scrape the location of a sample of schools in Spain.
Basic steps
For web scraping in R, you can fulfill almost all of your needs with the xml2 package. As you wander through the web, you’ll see many examples using the rvest package. xml2 and rvest are very similar so don’t feel you’re lacking behind for learning one and not the other. In addition to these two packages, we’ll need some other libraries for plotting locations on a map (ggplot2, sf, rnaturalearth), identifying who we are when we scrape (httr) and wrangling data (tidyverse).
Additionally, we’ll also need the package scrapex. In the real-world example that we’ll be doing below, we’ll be scraping data from the website www.buscocolegio.com to locate a sample of schools in Spain. However, throughout the tutorial we won’t be scraping the data directly from their real-website. What would happen to this tutorial if 6 months from now www.buscocolegio.com updates the design of their website? Everything from our real-world example would be lost.
Web scraping tutorials are usually very unstable precisely because of this. To circumvent that problem, I’ve saved a random sample of websites from some schools in www.buscocolegio.com into an R package called scrapex. Although the links we’ll be working on will be hosted locally on your machine, the HTML of the website should be very similar to the one hosted on the website (with the exception of some images/icons which were deleted on purpose to make the package lightweight).
You can install the package with:
# install.packages("devtools")
devtools::install_github("cimentadaj/scrapex")Now, let’s move on the fake data example and load all of our packages with:
library(xml2)
library(httr)
library(tidyverse)
library(sf)
library(rnaturalearth)
library(ggplot2)
library(scrapex)Let’s begin with a simple example. Below we define an XML string and look at its structure:
xml_test <- "<people>
<jason>
<person type='fictional'>
<first_name>
<married>
Jason
</married>
</first_name>
<last_name>
Bourne
</last_name>
<occupation>
Spy
</occupation>
</person>
</jason>
<carol>
<person type='real'>
<first_name>
<married>
Carol
</married>
</first_name>
<last_name>
Kalp
</last_name>
<occupation>
Scientist
</occupation>
</person>
</carol>
</people>
"
cat(xml_test)## <people>
## <jason>
## <person type='fictional'>
## <first_name>
## <married>
## Jason
## </married>
## </first_name>
## <last_name>
## Bourne
## </last_name>
## <occupation>
## Spy
## </occupation>
## </person>
## </jason>
## <carol>
## <person type='real'>
## <first_name>
## <married>
## Carol
## </married>
## </first_name>
## <last_name>
## Kalp
## </last_name>
## <occupation>
## Scientist
## </occupation>
## </person>
## </carol>
## </people>In XML and HTML the basic building blocks are something called tags. For example, the first tag in the structure shown above is <people>. This tag is matched by </people> at the end of the string:
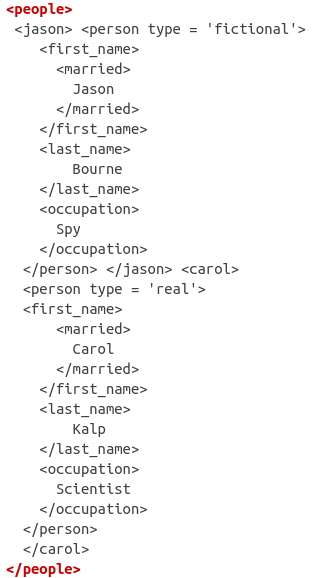
If you pay close attention, you’ll see that each tag in the XML structure has a beginning (signaled by <>) and an end (signaled by </>). For example, the next tag after <people> is <jason> and right before the tag <carol> is the end of the jason tag </jason>.

Similarly, you’ll find that the <carol> tag is also matched by a </carol> finishing tag.
In theory, tags can have whatever meaning you attach to them (such as <people> or <occupation>). However, in practice there are hundreds of tags which are standard in websites (for example, here). If you’re just getting started, there’s no need for you to learn them but as you progress in web scraping, you’ll start to recognize them (one brief example is <strong> which simply bolds text in a website).
The xml2 package was designed to read XML strings and to navigate the tree structure to extract information. For example, let’s read in the XML data from our fake example and look at its general structure:
xml_raw <- read_xml(xml_test)
xml_structure(xml_raw)## <people>
## <jason>
## <person [type]>
## <first_name>
## <married>
## {text}
## <last_name>
## {text}
## <occupation>
## {text}
## <carol>
## <person [type]>
## <first_name>
## <married>
## {text}
## <last_name>
## {text}
## <occupation>
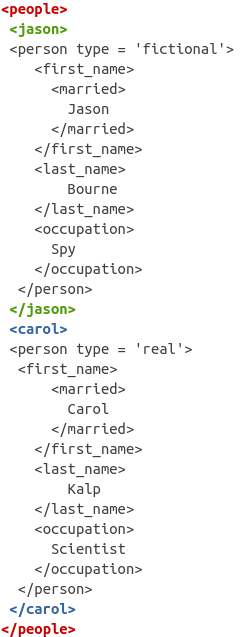
## {text}You can see that the structure is tree-based, meaning that tags such as <jason> and <carol> are nested within the <people> tag. In XML jargon, <people> is the root node, whereas <jason> and <carol> are the child nodes from <people>.
In more detail, the structure is as follows:
- The root node is
<people> - The child nodes are
<jason>and<carol> - Then each child node has nodes
<first_name>,<married>,<last_name>and<occupation>nested within them.
Put another way, if something is nested within a node, then the nested node is a child of the upper-level node. In our example, the root node is <people> so we can check which are its children:
# xml_child returns only one child (specified in search)
# Here, jason is the first child
xml_child(xml_raw, search = 1)## {xml_node}
## <jason>
## [1] <person type="fictional">\n <first_name>\n <married>\n Ja ...# Here, carol is the second child
xml_child(xml_raw, search = 2)## {xml_node}
## <carol>
## [1] <person type="real">\n <first_name>\n <married>\n Carol\n ...# Use xml_children to extract **all** children
child_xml <- xml_children(xml_raw)
child_xml## {xml_nodeset (2)}
## [1] <jason>\n <person type="fictional">\n <first_name>\n <marri ...
## [2] <carol>\n <person type="real">\n <first_name>\n <married>\n ...Tags can also have different attributes which are usually specified as <fake_tag attribute='fake'> and ended as usual with </fake_tag>. If you look at the XML structure of our example, you’ll notice that each <person> tag has an attribute called type. As you’ll see in our real-world example, extracting these attributes is often the aim of our scraping adventure. Using xml2, we can extract all attributes that match a specific name with xml_attrs.
# Extract the attribute type from all nodes
xml_attrs(child_xml, "type")## [[1]]
## named character(0)
##
## [[2]]
## named character(0)Wait, why didn’t this work? Well, if you look at the output of child_xml, we have two nodes on which are for <jason> and <carol>.
child_xml## {xml_nodeset (2)}
## [1] <jason>\n <person type="fictional">\n <first_name>\n <marri ...
## [2] <carol>\n <person type="real">\n <first_name>\n <married>\n ...Do these tags have an attribute? No, because if they did, they would have something like <jason type='fake_tag'>. What we need is to look down at the <person> tag within <jason> and <carol> and extract the attribute from <person>.
Does this sound familiar? Both <jason> and <carol> have an associated <person> tag below them, making them their children. We can just go down one level by running xml_children on these tags and extract them.
# We go down one level of children
person_nodes <- xml_children(child_xml)
# <person> is now the main node, so we can extract attributes
person_nodes## {xml_nodeset (2)}
## [1] <person type="fictional">\n <first_name>\n <married>\n Ja ...
## [2] <person type="real">\n <first_name>\n <married>\n Carol\n ...# Both type attributes
xml_attrs(person_nodes, "type")## [[1]]
## type
## "fictional"
##
## [[2]]
## type
## "real"Using the xml_path function you can even find the ‘address’ of these nodes to retrieve specific tags without having to write down xml_children many times. For example:
# Specific address of each person tag for the whole xml tree
# only using the `person_nodes`
xml_path(person_nodes)## [1] "/people/jason/person" "/people/carol/person"We have the ‘address’ of specific tags in the tree but how do we extract them automatically? To extract specific ‘addresses’ of this XML tree, the main function we’ll use is xml_find_all. This function accepts the XML tree and an ‘address’ string. We can use very simple strings, such as the one given by xml_path:
# You can use results from xml_path like directories
xml_find_all(xml_raw, "/people/jason/person")## {xml_nodeset (1)}
## [1] <person type="fictional">\n <first_name>\n <married>\n Ja ...The expression above is asking for the node "/people/jason/person". This will return the same as saying xml_raw %>% xml_child(search = 1). For deeply nested trees, xml_find_all will be many times much cleaner than calling xml_child recursively many times.
However, in most cases the ‘addresses’ used in xml_find_all come from a separate language called XPath (in fact, the ‘address’ we’ve been looking at is XPath). XPath is a complex language (such as regular expressions for strings) which is beyond this brief tutorial. However, with the examples we’ve seen so far, we can use some basic XPath which we’ll need later on.
To extract all the tags in a document, we can use //name_of_tag.
# Search for all 'married' nodes
xml_find_all(xml_raw, "//married")## {xml_nodeset (2)}
## [1] <married>\n Jason\n </married>
## [2] <married>\n Carol\n </married>With the previous XPath, we’re searching for all married tags within the complete XML tree. The result returns all married nodes (I use the words tags and nodes interchangeably) in the complete tree structure. Another example would be finding all <occupation> tags:
xml_find_all(xml_raw, "//occupation")## {xml_nodeset (2)}
## [1] <occupation>\n Spy\n </occupation>
## [2] <occupation>\n Scientist\n </occupation>If you want to find any other tag you can replace "//occupation" with your tag of interest and xml_find_all will find all of them.
If you wanted to find all tags below your current node, you only need to add a . at the beginning: ".//occupation". For example, if we dived into the <jason> tag and we wanted his <occupation> tag, "//occupation" will returns all <occupation> tags. Instead, ".//occupation" will return only the found tags below the current tag. For example:
xml_raw %>%
# Dive only into Jason's tag
xml_child(search = 1) %>%
xml_find_all(".//occupation")## {xml_nodeset (1)}
## [1] <occupation>\n Spy\n </occupation># Instead, the wrong way would have been:
xml_raw %>%
# Dive only into Jason's tag
xml_child(search = 1) %>%
# Here we get both occupation tags
xml_find_all("//occupation")## {xml_nodeset (2)}
## [1] <occupation>\n Spy\n </occupation>
## [2] <occupation>\n Scientist\n </occupation>The first example only returns <jason>’s occupation whereas the second returned all occupations, regardless of where you are in the tree.
XPath also allows you to identify tags that contain only one specific attribute, such as the one’s we saw earlier. For example, to filter all <person> tags with the attribute filter set to fictional, we could do it with:
# Give me all the tags 'person' that have an attribute type='fictional'
xml_raw %>%
xml_find_all("//person[@type='fictional']")## {xml_nodeset (1)}
## [1] <person type="fictional">\n <first_name>\n <married>\n Ja ...If you wanted to do the same but for the tags below your current nodes, the same trick we learned earlier would work: ".//person[@type='fictional']". These are just some primers that can help you jump easily to using XPath, but I encourage you to look at other examples on the web, as complex websites often require complex XPath expressions.
Before we begin our real-word example, you might be asking yourself how you can actually extract the text/numeric data from these nodes. Well, that’s easy: xml_text.
xml_raw %>%
xml_find_all(".//occupation") %>%
xml_text()## [1] "\n Spy\n " "\n Scientist\n "Once you’ve narrowed down your tree-based search to one single piece of text or numbers, xml_text() will extract that for you (there’s also xml_double and xml_integer for extracting numbers). As I said, XPath is really a huge language. If you’re interested, this XPath cheat sheets have helped me a lot to learn tricks for easy scraping.
Real-world example
We’re interested in making a list of many schools in Spain and visualizing their location. This can be useful for many things such as matching population density of children across different regions to school locations. The website www.buscocolegio.com contains a database of schools similar to what we’re looking for. As described at the beginning, instead we’re going to use scrapex which has the function spanish_schools_ex() containing the links to a sample of websites from different schools saved locally on your computer.
Let’s look at an example for one school.
school_links <- spanish_schools_ex()
# Keep only the HTML file of one particular school.
school_url <- school_links[13]
school_url## [1] "/usr/local/lib/R/site-library/scrapex/extdata/spanish_schools_ex/school_3006839.html"If you’re interested in looking at the website interactively in your browser, you can do it with browseURL(prep_browser(school_url)). Let’s read the HTML (XML and HTML are usually interchangeable, so here we use read_html).
# Here we use `read_html` because `read_xml` is throwing an error
# when attempting to read. However, everything we've discussed
# should be the same.
school_raw <- read_html(school_url) %>% xml_child()
school_raw## {html_node}
## <head>
## [1] <title>Aquí encontrarás toda la información necesaria sobre CEIP SA ...
## [2] <meta charset="utf-8">\n
## [3] <meta name="viewport" content="width=device-width, initial-scale=1, ...
## [4] <meta http-equiv="x-ua-compatible" content="ie=edge">\n
## [5] <meta name="author" content="BuscoColegio">\n
## [6] <meta name="description" content="Encuentra toda la información nec ...
## [7] <meta name="keywords" content="opiniones SANCHIS GUARNER, contacto ...
## [8] <link rel="shortcut icon" href="/favicon.ico">\n
## [9] <link rel="stylesheet" href="//fonts.googleapis.com/css?family=Robo ...
## [10] <link rel="stylesheet" href="https://s3.eu-west-3.amazonaws.com/bus ...
## [11] <link rel="stylesheet" href="/assets/vendor/icon-awesome/css/font-a ...
## [12] <link rel="stylesheet" href="/assets/vendor/icon-line/css/simple-li ...
## [13] <link rel="stylesheet" href="/assets/vendor/icon-line-pro/style.css ...
## [14] <link rel="stylesheet" href="/assets/vendor/icon-hs/style.css">\n
## [15] <link rel="stylesheet" href="https://s3.eu-west-3.amazonaws.com/bus ...
## [16] <link rel="stylesheet" href="https://s3.eu-west-3.amazonaws.com/bus ...
## [17] <link rel="stylesheet" href="https://s3.eu-west-3.amazonaws.com/bus ...
## [18] <link rel="stylesheet" href="https://s3.eu-west-3.amazonaws.com/bus ...
## [19] <link rel="stylesheet" href="https://s3.eu-west-3.amazonaws.com/bus ...
## [20] <link rel="stylesheet" href="https://s3.eu-west-3.amazonaws.com/bus ...
## ...Web scraping strategies are very specific to the website you’re after. You have to get very familiar with the website you’re interested to be able to match perfectly the information you’re looking for. In many cases, scraping two websites will require vastly different strategies. For this particular example, we’re only interested in figuring out the location of each school so we only have to extract its location.
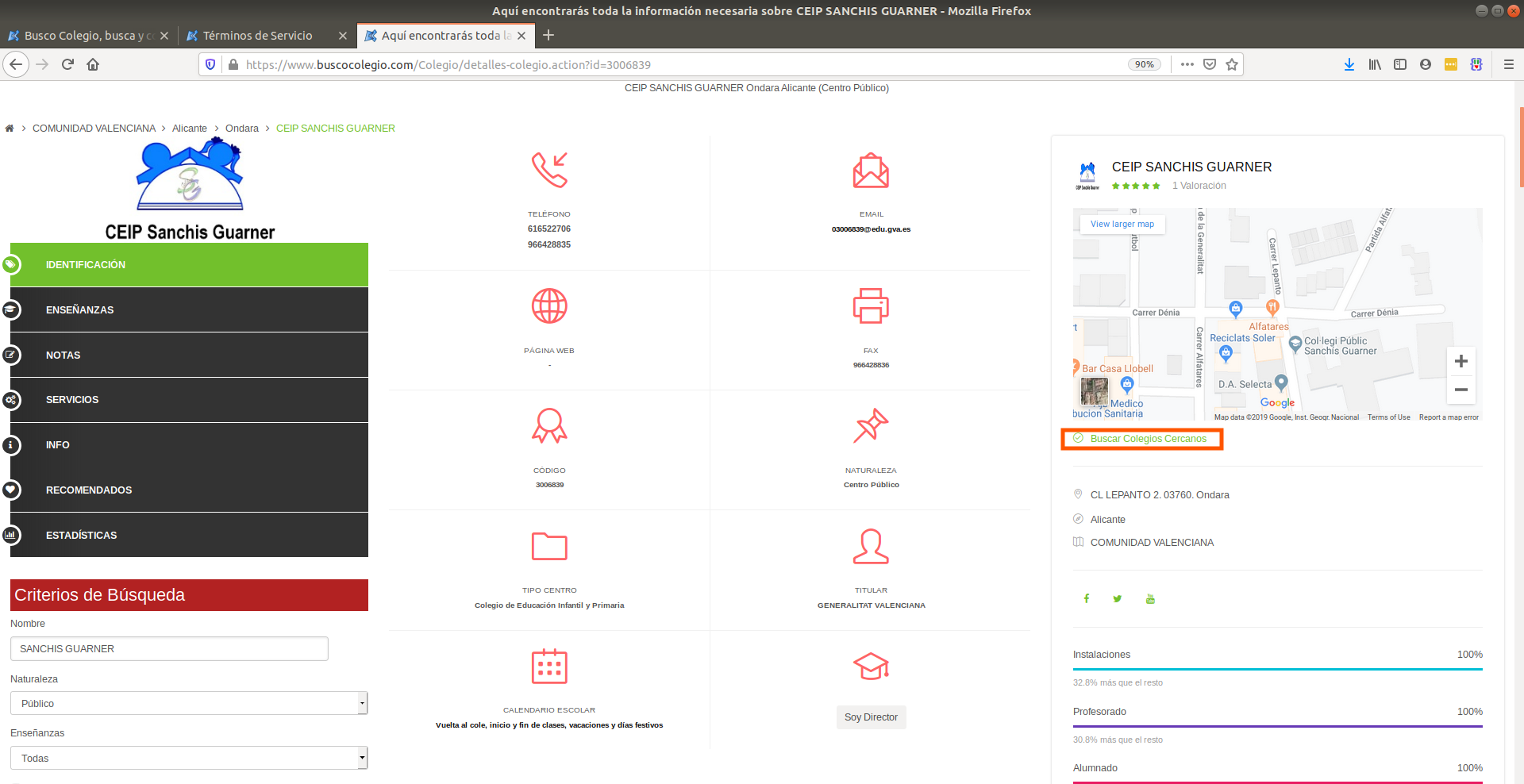
In the image above you’ll find a typical school’s website in wwww.buscocolegio.com. The website has a lot of information, but we’re only interested in the button that is circled by the orange rectangle. If you can’t find it easily, it’s below the Google Maps on the right which says “Buscar colegio cercano”.
When you click on this button, this actually points you towards the coordinates of the school so we just have to find a way of figuring out how to click this button or figure out how to get its information. All browsers allow you to do this if you press CTRL + SHIFT + c at the same time (Firefox and Chrome support this hotkey). If a window on the right popped in full of code, then you’re on the right track:
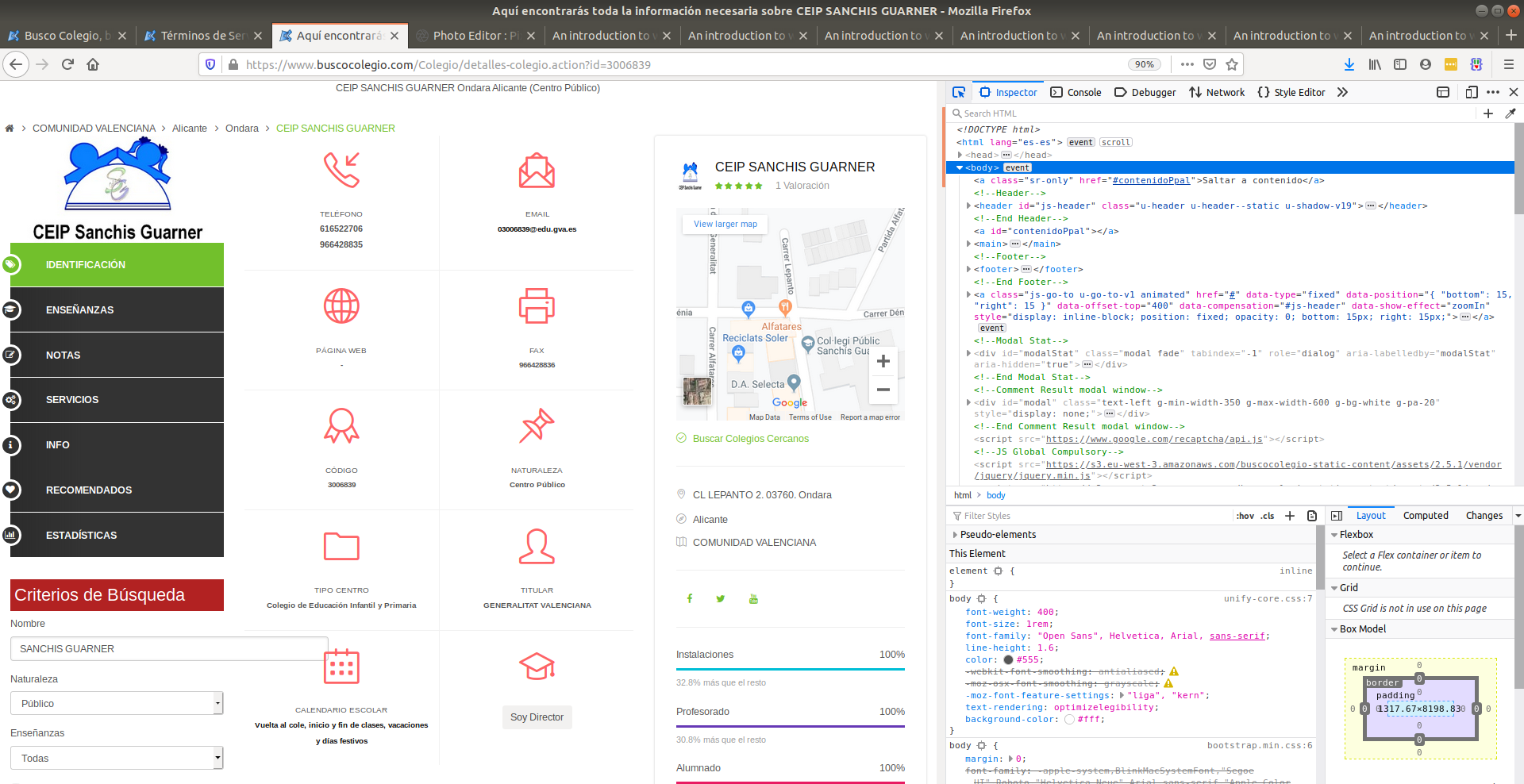
Here we can search the source code of the website. If you place your mouse pointer over the lines of code from this right-most window, you’ll see sections of the website being highlighted in blue. This indicates which parts of the code refer to which parts of the website. Luckily for us, we don’t have to search the complete source code to find that specific location. We can approximate our search by typing the text we’re looking for in the search bar at the top of the right window:
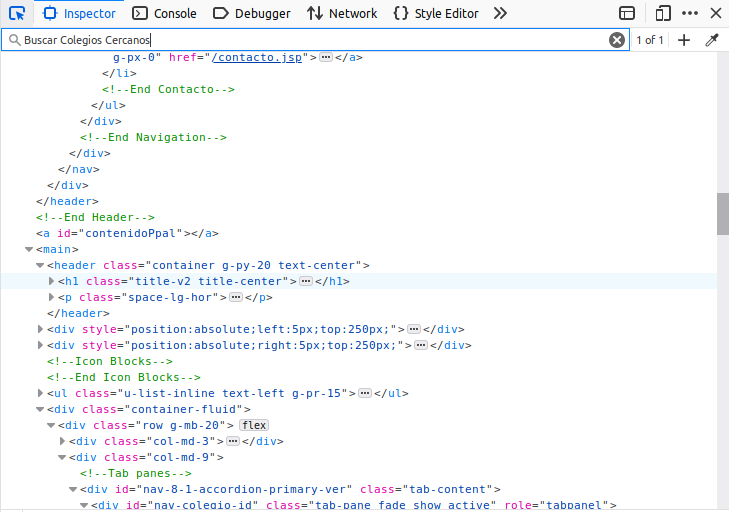
After we click enter, we’ll be automatically directed to the tag that has the information that we want.
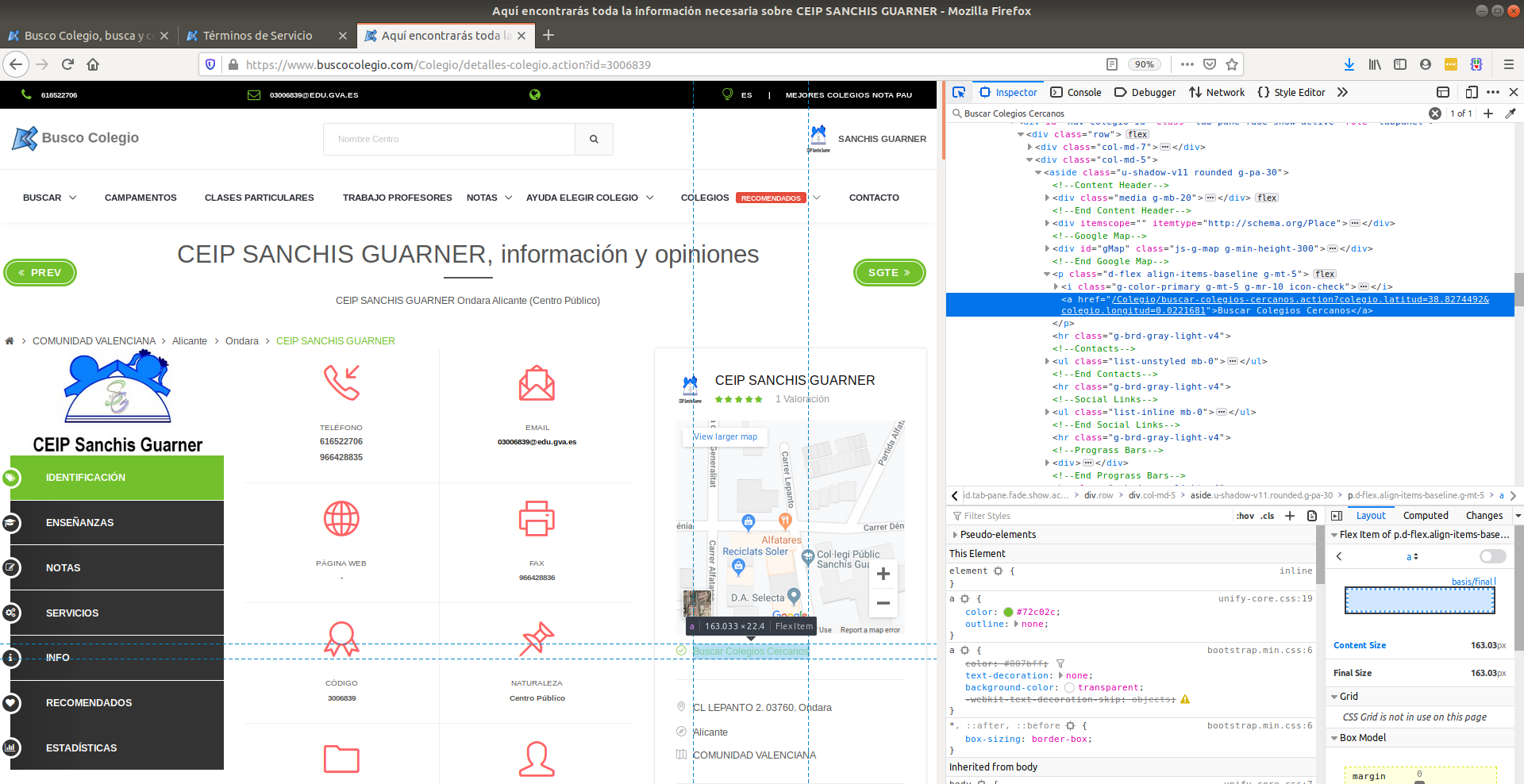
More specifically, we can see that the latitude and longitude of schools are found in an attributed called href in a tag <a>:
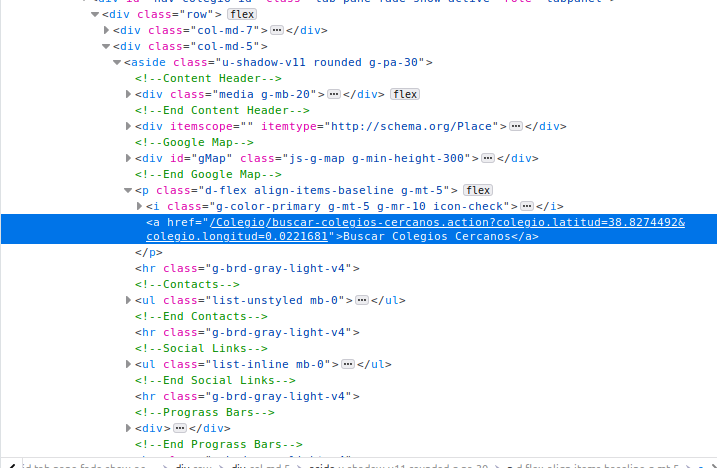
Can you see the latitude and longitude fields in the text highlighted blue? It’s hidden in-between words. That is precisely the type of information we’re after. Extracting all <a> tags from the website (hint: XPath similar to "//a") will yield hundreds of matches because <a> is a very common tag. Moreover, refining the search to <a> tags which have an href attribute will also yield hundreds of matches because href is the standard attribute to attach links within websites. We need to narrow down our search within the website.
One strategy is to find the ‘father’ or ‘grandfather’ node of this particular <a> tag and then match a node which has that same sequence of grandfather -> father -> child node. By looking at the structure of this small XML snippet from the right-most window, we see that the ‘grandfather’ of this <a> tag is <p class="d-flex align-items-baseline g-mt-5'> which has a particularly long attribute named class.
Don’t be intimidated by these tag names and long attributes. I also don’t know what any of these attributes mean. But what I do know is that this is the ‘grandfather’ of the <a> tag I’m interested in. So using our XPath skills, let’s search for that <p> tag and see if we get only one match.
# Search for all <p> tags with that class in the document
school_raw %>%
xml_find_all("//p[@class='d-flex align-items-baseline g-mt-5']")## {xml_nodeset (1)}
## [1] <p class="d-flex align-items-baseline g-mt-5">\r\n\t ...Only one match, so this is good news. This means that we can uniquely identify this particular <p> tag. Let’s refine the search to say: Find all <a> tags which are children of that specific <p> tag. This only means I’ll add a "//a" to the previous expression. Since there is only one <p> tag with the class, we’re interested in checking whether there is more than one <a> tag below this <p> tag.
school_raw %>%
xml_find_all("//p[@class='d-flex align-items-baseline g-mt-5']//a")## {xml_nodeset (1)}
## [1] <a href="/Colegio/buscar-colegios-cercanos.action?colegio.latitud=38 ...There we go! We can see the specific href that contains the latitude and longitude data we’re interested in. How do we extract the href attribute? Using xml_attr as we did before!
location_str <-
school_raw %>%
xml_find_all("//p[@class='d-flex align-items-baseline g-mt-5']//a") %>%
xml_attr(attr = "href")
location_str## [1] "/Colegio/buscar-colegios-cercanos.action?colegio.latitud=38.8274492&colegio.longitud=0.0221681"Ok, now we need some regex skills to get only the latitude and longitude (regex expressions are used to search for patterns inside a string, such as for example a date. See here for some examples):
location <-
location_str %>%
str_extract_all("=.+$") %>%
str_replace_all("=|colegio\\.longitud", "") %>%
str_split("&") %>%
.[[1]]
location## [1] "38.8274492" "0.0221681"Ok, so we got the information we needed for one single school. Let’s turn that into a function so we can pass only the school’s link and get the coordinates back.
Before we do that, I will set something called my User-Agent. In short, the User-Agent is who you are. It is good practice to identify the person who is scraping the website because if you’re causing any trouble on the website, the website can directly identify who is causing problems. You can figure out your user agent here and paste it in the string below. In addition, I will add a time sleep of 5 seconds to the function because we want to make sure we don’t cause any troubles to the website we’re scraping due to an overload of requests.
# This sets your `User-Agent` globally so that all requests are
# identified with this `User-Agent`
set_config(
user_agent("Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:70.0) Gecko/20100101 Firefox/70.0")
)
# Collapse all of the code from above into one function called
# school grabber
school_grabber <- function(school_url) {
# We add a time sleep of 5 seconds to avoid
# sending too many quick requests to the website
Sys.sleep(5)
school_raw <- read_html(school_url) %>% xml_child()
location_str <-
school_raw %>%
xml_find_all("//p[@class='d-flex align-items-baseline g-mt-5']//a") %>%
xml_attr(attr = "href")
location <-
location_str %>%
str_extract_all("=.+$") %>%
str_replace_all("=|colegio\\.longitud", "") %>%
str_split("&") %>%
.[[1]]
# Turn into a data frame
data.frame(
latitude = location[1],
longitude = location[2],
stringsAsFactors = FALSE
)
}
school_grabber(school_url)## latitude longitude
## 1 38.8274492 0.0221681Ok, so it’s working. The only thing left is to extract this for many schools. As shown earlier, scrapex contains a list of 27 school links that we can automatically scrape. Let’s loop over those, get the information of coordinates for each and collapse all of them into a data frame.
res <- map_dfr(school_links, school_grabber)
res## latitude longitude
## 1 42.72779 -8.6567935
## 2 43.24439 -8.8921645
## 3 38.95592 -1.2255769
## 4 39.18657 -1.6225903
## 5 40.38245 -3.6410388
## 6 40.22929 -3.1106322
## 7 40.43860 -3.6970366
## 8 40.33514 -3.5155669
## 9 40.50546 -3.3738441
## 10 40.63826 -3.4537107
## 11 40.38543 -3.6639500
## 12 37.76485 -1.5030467
## 13 38.82745 0.0221681
## 14 40.99434 -5.6224391
## 15 40.99434 -5.6224391
## 16 40.56037 -5.6703725
## 17 40.99434 -5.6224391
## 18 40.99434 -5.6224391
## 19 41.13593 0.9901905
## 20 41.26155 1.1670507
## 21 41.22851 0.5461471
## 22 41.14580 0.8199749
## 23 41.18341 0.5680564
## 24 42.07820 1.8203155
## 25 42.25245 1.8621546
## 26 41.73767 1.8383666
## 27 41.62345 2.0013628So now that we have the locations of these schools, let’s plot them:
res <- mutate_all(res, as.numeric)
sp_sf <-
ne_countries(scale = "large", country = "Spain", returnclass = "sf") %>%
st_transform(crs = 4326)
ggplot(sp_sf) +
geom_sf() +
geom_point(data = res, aes(x = longitude, y = latitude)) +
coord_sf(xlim = c(-20, 10), ylim = c(25, 45)) +
theme_minimal() +
ggtitle("Sample of schools in Spain")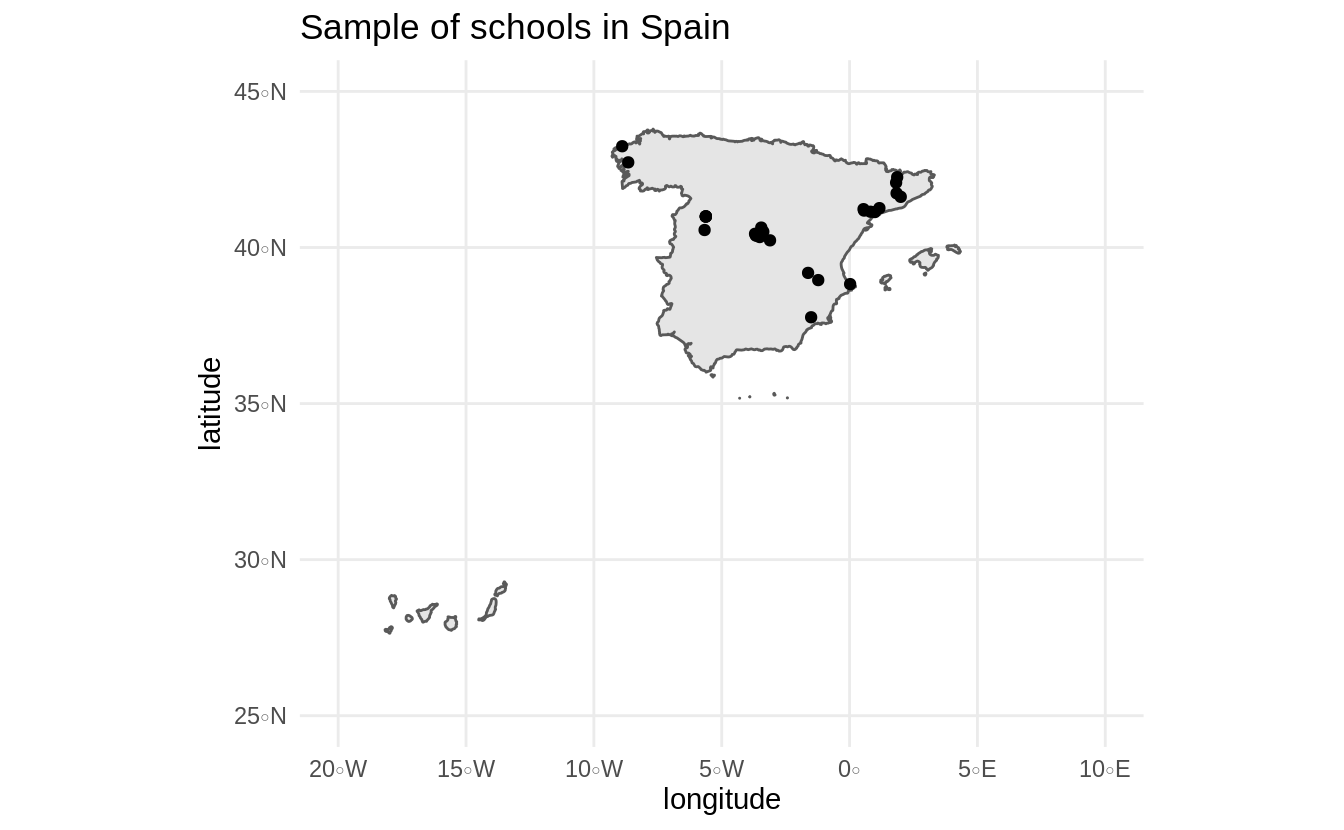
There we go! We went from literally no information at the beginning of this tutorial to interpretable and summarized information only using web data. We can see some schools in Madrid (center) as well in other regions of Spain, including Catalonia and Galicia.
This marks the end of our scraping adventure but before we finish, I want to mention some of the ethical guidelines for web scraping. Scraping is extremely useful for us but can give headaches to other people maintaining the website of interest. Here’s a list of ethical guidelines you should always follow:
Read the terms and services: many websites prohibit web scraping and you could be in a breach of privacy by scraping the data. One famous example.
Check the
robots.txtfile. This is a file that most websites have (www.buscocolegio.comdoes not) which tell you which specific paths inside the website are scrapable and which are not. See here for an explanation of what robots.txt look like and where to find them.Some websites are supported by very big servers, which means you can send 4-5 website requests per second. Others, such as
www.buscocolegio.comare not. It’s good practice to always put a time sleep between your requests. In our example, I set it to 5 seconds because this is a small website and we don’t want to crash their servers.When making requests, there are computational ways of identifying yourself. For example, every request (such as the one’s we do) can have something called a
User-Agent. It is good practice to include yourself in as theUser-Agent(as we did in our code) because the admin of the server can directly identify if someone’s causing problems due to their web scraping.Limit your scraping to non-busy hours such as overnight. This can help reduce the chances of collapsing the website since fewer people are visiting websites in the evening.
You can read more about these ethical issues here.
Wrap up
This tutorial introduced you to basic concepts in web scraping and applied them in a real-world setting. Web scraping is a vast field in computer science (you can find entire books on the subject such as this). We covered some basic techniques which I think can take you a long way but there’s definitely more to learn. For those curious about where to turn, I’m looking forward to the upcoming book “A Field Guide for Web Scraping and Accessing APIs with R” by Bob Rudis, which should be released in the near future. Now go scrape some websites ethically!